Pull US Census Data Using Cognos Analytics via the Bureau’s API (Part 2: Manual Pull Boogaloo)

In my previous post on this subject, we discovered that the interesting new way (as of 11.1.7) to use REST API JSON responses as data sources in Cognos Analytics didn’t quite work as expected for our routine US Census Bureau use case. This is due to the nonstandard JSON format response from the US Census Bureau API. Basically, the Census API returns nonstandard JSON that uses nested arrays with values separated by a comma and headers on the first row rather than conventional JSON objects with key value pairs. The Progress DataDirect Autonomous REST connector included with Cognos Analytics 11.1.7 cannot yet autonomously handle the unconventional JSON that the US Census Bureau sends it. Progress, it seems, recognizes that they’d like to improve this and has assigned the enhancement to their dev team. We were hoping that Progress would be able to include the enhancement with Cognos Analytics Fix Pack 2 (released just a few weeks ago), but that’s not the case. Regardless, it should be improved shorty in an upcoming fix pack, interim fix, or release. Once improved, you’ll simply be able to use the Progress DataDirect Autonomous REST connector to get US Census Bureau data into your Cognos Analytics environments essentially via a simple JDBC connection. In the meantime, here are some manual workaround options to enable use of US Census Bureau data in your Cognos Analytics environments.
For our use cases below, we’ll go after US Census ACS data that shows estimates of the total population 25 years and older with a bachelor’s degree or higher in science and engineering related fields for each state. Don’t forget about the excellent documentation that the US Census Bureau provides to help you understand the data available within a subject. See my previous post for a deeper dive on the US Census data available as a whole.
Option 1: Keep It Simple
For some use cases, an infrequent or single simple point in time grab of US Census data may just do the trick. To make this simple case happen…
Pop https://api.census.gov/data/2019/acs/acs1/subject?get=NAME,S1502_C02_003E&for=state:* into your browser. Each browser is different in the way it displays JSON responses. Firefox, to me, does the best job by allowing you to toggle between JSON, Raw Data, and Headers views.

Just click Save from the toolbar (or right click results and Save Page As) and change the extension to .csv or txt, for example. From there, you’ll have some cleanup to do to get rid of characters you don’t want in your data ( like… “, [[, ]], [, ] ).

Once clean, simply upload it to Cognos Analytics via normal means (New > Upload Files) from within the Cognos UI, then create data modules and such from there.
For future point in time updates of data, you could simply repeat the manual steps above, then append or refresh that uploaded file in Cognos Analytics with your fresh data.
Pros & cons: Manual, involves several steps but easily repeatable, technologically simple, common, anyone can do it.
Option 2: Automate the Data Pull and Prep
For other use cases, you might need to do this process more frequently and don’t want to do as many of the manual steps above. In this case, you could schedule a small Python script to do much of the above using a few libraries like pandas, json, and request…
Here’s an example script that does all of the steps above to get data from the API, do the data cleansing, then save the output in the right way and in the right place.

The script creates a csv that is immediately ready to upload to Cognos Analytics. No connect to API or data cleansing steps required.

Of course, you could use any scheduler to fire that .py script at some regular interval in order to get latest data from US Census data.
You would then need to upload the fresh data into Cognos Analytics. Append or refresh the uploaded file as needed.
Pros & cons: 75% automated, requires Python and scheduler, still have to manually update file in Cognos Analytics.
Option 3: Build It Once and Automate Fully
For other cases, you might want full automation. If you have your Cognos environment hooked up to Jupyter Notebook Server, you could throw all of this into a notebook that grabs the data, transforms it, then updates or creates the uploaded file in your Cognos environment (your data source).
Modify the Python script above to suit your needs and put it in a Jupyter Notebook. Essentially, you want the call to the API and the reformatting of data into a data frame from the script above.
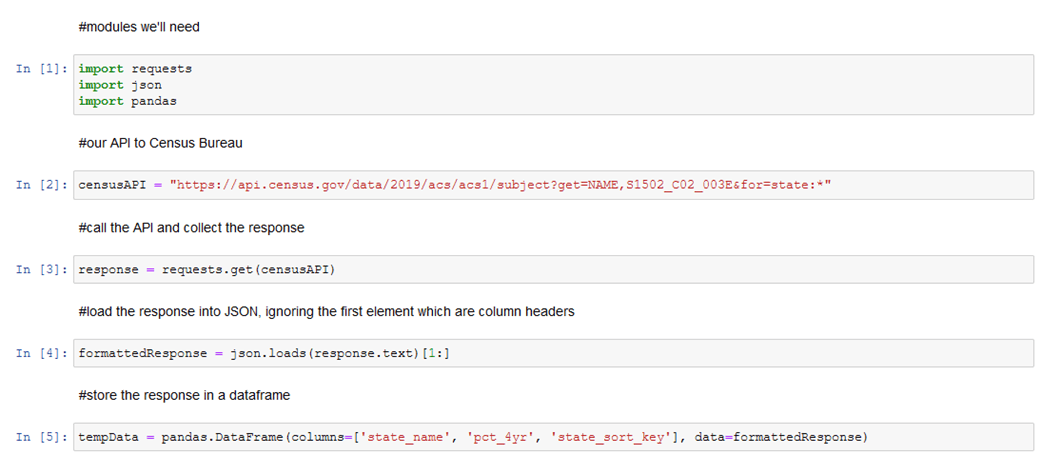
From there, you could build out your Notebook just a bit more to take the well-formed data in the pandas.DataFrame and write it to an uploaded file in Cognos Analytics using CADataConnector.write_data.
At this point, you could just schedule that Notebook using native Cognos Analytics scheduling mechanism and you’ll have fresh data in an automated fashion.
Pros & cons: Requires Cognos Analytics for Jupyter Notebook Server, build once and reap rewards, technologically more difficult to implement, easy to support.
Wrap Up
Of course, these workarounds become moot if Progress enhances their DataDirect Autonomous REST connector to be able to use the nonstandard US Census Bureau data. Until then, I hope the workarounds above have shed some light on different ways to get unique data into your Cognos Analytics environments.
Next Steps
PMsquare has helped customers successfully utilize data from many different sources using various methods. For help pulling US Census data into your Cognos Analytics implementation, contact one of our solutions architects.
We hope you found this article informative. Be sure to subscribe to our newsletter for data and analytics news, updates, and insights delivered directly to your inbox.
