5 Ways Your AI Projects Fail, Part 3

Strategic AI Failures
Introduction
The recurring perception that artificial intelligence, AI, is somehow magical and can create something from nothing leads many projects astray. That’s part of the reason that the 2019 Price Waterhouse CEO Survey shows fewer than half of US companies are embarking on strategic AI initiatives – the risk of failure is substantial. In this series, we’re examining the most common ways AI projects will fail for companies in the beginning of your AI journey. Be on the lookout for these failures – and ways to remediate or prevent them – in your own AI initiatives.
Part 3: Data-Related AI Failures
Before we can discuss failures, let’s refresh our memories of what the AI project lifecycle is to understand what should be happening.

Grab the full-page PDF of the lifecycle from our Instant Insight on the topic and follow along.
Now that we’ve identified the major problems in overall strategy, let’s turn our eyes to the major problems we are likely to encounter in the data portion of the lifecycle:
Data Requirements
Data Collection
Exploratory Data Analysis
Data Preparation
Data Requirements Failures
Data requirements are the technical specifications of what data you will need for your project, who is responsible for that data, where and how it is stored and used, and what measures you’ve taken to protect and optimize it for usage.
An example of a data requirements framework would the Trust Insights 6C Framework for Data Quality.
Data requirements failures are most common in projects that have multiple stages like a proof of concept and a production phase. Shortcuts and ‘hacks’ that make a proof of concept work often don’t scale in production.
Equally important, data requirements often change over time, especially as projects mature. What was effective or useful in the beginning of the project may not be in full production mode.
The antidote to data requirements failures are careful alignment with business requirements, thorough planning, knowledge of what systems you’ll be using for machine learning (and their data requirements) and extensive preparation and forethought as to what could possibly go wrong or change.
For example, suppose we were making a social media analytics model with an eye towards optimizing the content we publish on social media. What could go wrong? From long experience, we know it’s likely that:
Over time, there will be API changes that may change the format, frequency, or integrity of our data
Social networks may restrict or remove data (Instagram likes)
Social networks may change how certain data is defined (Facebook video view versus YouTube video view)
People may change what networks they use (MySpace)
Laws could change about what data we are permitted to collect and store (GDPR)
Vendors change, and we change vendors.
A format used by one vendor may be incompatible with another (especially in machine learning models)
And this is just the tip of the iceberg. The general best practice frameworks to assess potential risks are performing SWOT and PESTLE analyses for your data.
Once we anticipate likely scenarios of change, we better understand what kinds of data we will need, what we should plan for, what we might need to change down the road, and how to manage those changes in our raw material, data. The final part of this process is to document our data needs so that as things change, we know what we started with.
Data Collection
Data collection is an area in the lifecycle that has fewer things that typically go wrong than other parts; companies have become quite adept at collecting data for the most part.
Where things do tend to go wrong in data collection is in the process itself. As many processes can and are automated, data collection can silently fail and no one knows until they go to use the data.
For example, a piece of software may fail, a scheduler may fail to run, or encounter unexpected data errors. If the software that’s collecting data hasn’t been programmed to alert users when it runs into errors, you may not know.
Another common occurrence, especially with marketing data from third-party providers like social networks, is a change in the data format that’s unannounced or poorly documented by the third party. For example, Facebook has changed its way of specifying a live video several times; we’ve had to adapt our software to match and anticipate these changes.
The antidote for failures in data collection is regular maintenance and validation. Ideally, the software you use has regular, frequent checks built into it; that said, it’s still worthwhile for a person to check in on the software regularly, and as frequently as the importance of the data mandates. The easiest rule of thumb is to divide the data importance in half and check at those intervals. If you need data once daily, check every half day. If you need data once a week, check in half week intervals.
Exploratory Data Analysis
The formal discipline and process of exploratory data analysis – EDA – is an area fraught with failures for one simple reason:
Most companies fail to do it.
For those few companies that do EDA, most do it in a haphazard, slipshod way with no clearly defined process.
What is EDA? As the name implies, it’s all about exploring your data to learn its characteristics and anomalies. The formal EDA process looks like this:

Where companies go wrong, assuming they do it at all, is by skipping steps. This is especially common for companies that don’t have trained data scientists and data analysts on staff. When a project first kicks off, a thorough EDA is essential. Until you perform EDA, you don’t know what you don’t know, which creates an enormous risk of failure for your project.
An important thing to realize at this point in the process is that the first three steps can be, and for mission-critical projects often are, iterative. You may discover anomalies or gaps in the EDA process that sends you back to the beginning, back to data requirements, or to make repairs in data collection.
Data Preparation
The final stage in this process is the part where, if you’ve done the first three steps well, it should be most error-free. Data preparation takes the data we’ve specified, collected, and analyzed, and prepares it for use by machine learning software. Common steps at this point include correcting errors discovered in EDA, imputing missing data, and converting data from one type to another.
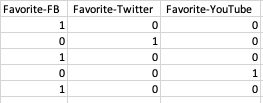
The most common mistakes in data preparation involve misalignment with the AI tools you’ll be using for modeling. For example, if you’re doing traditional deep learning (without any automated data preparation), you’ll have to transform certain variables into deep learning-compatible formats, such as sparsifying categorical variables. Here’s a simple example. Suppose you have a column in a spreadsheet that indicates a person’s favorite social network:

This would seem to be fairly straightforward, but a traditional deep learning network can’t understand this at all. The software would require the data to be formatted like this:
Conclusion
The antidote to failures in data preparation is knowing what data formats your software needs, which should have been defined in the data requirements stage.
Next: What Can Go Wrong in Modeling?
It’s essential we get the data stage of the process as correct as possible. Not only is data the underpinning of machine learning and AI, but it’s also a massive cost-saving measure. The process of building a machine learning model can be time and resource-intensive. If our data quality is poor, we may invest massive amounts of resources in modeling, only to have the model fail and need to start over again. Avoid this costly failure by doing data right!
We’ll next turn our eyes towards what things will most likely go wrong in the modeling portion of the lifecycle. Stay tuned!
Next Steps
We hope you found this article informative. Be sure to subscribe to our newsletter for data and analytics news, updates, and insights that are delivered directly to your inbox.
If you have any questions or would like PMsquare to provide guidance and support for your analytics solution, contact us today.
