

Share




Andreea Stanovici, May 8, 2023
Get the Best Solution for
Your Business Today!
AWS Glue is a server-less data integration service that provides all capabilities needed to categorize, clean, enrich and move the data between data stores. AWS Glue is a powerful ETL tool that reduces and automates a significant portion of the effort required for data integration. It is much more cost-effective than most if not all ETL tools on the market, charging 44 cents per DPU hour. To fully leverage AWS Glue’s capabilities for production workloads, the service must be fine-tuned with proper configurations to reduce job runtime and increase resource availability.
Table of Contents
Setting up/Configuration
AWS Glue jobs are typically orchestrated within AWS Glue workflows. The workflows set various triggers to initiate jobs in a specific order. Even though AWS Glue is a “server-less” solution, real servers managed by AWS are used. Under the hood, the service uses groups of container clusters to execute jobs. One issue our team initially encountered with our AWS Glue jobs was long and expensive runtimes for jobs that were handling a low volume of data during our ETL run. When running the jobs outside of ETL hours, the job runtime was not problematic. We discovered that one of the primary causes of the longer run times was due to the lack of resource availability. After fine-tuning the jobs, we were able to cut many of the job runtimes in half, speeding up the overall ETL and lowering the time billed for job executions.
Ensuring enough resources are available for the server-less service is the first step to avoiding bottlenecks within your pipeline. It’s likely that multiple jobs would be utilizing the same cluster of underlying resources at the same time due to the number of jobs running simultaneously within different workflows. If many of the required resources for the job are already in use, AWS Glue often stalls until the resources are available. Ensuring resource availability reduces the risk of a bottleneck stemming from the service and enables the jobs to use different resources instead of waiting for the same cluster to become available.
It’s important to understand how the AWS Glue determines which resources are going to be used for job execution. When a job is initiated, a new isolated Spark environment is created for each combination of a customer account ID, subnet ID, Identity access management (IAM) role, worker type, and security group. Assuming all the jobs are being deployed from the same AWS account, the account number remains the same throughout. Let’s dive deeper into the factors that can be modified or verified to ensure resource availability for the jobs.
1) AWS Virtual Private Cloud (VPC) and Subnet
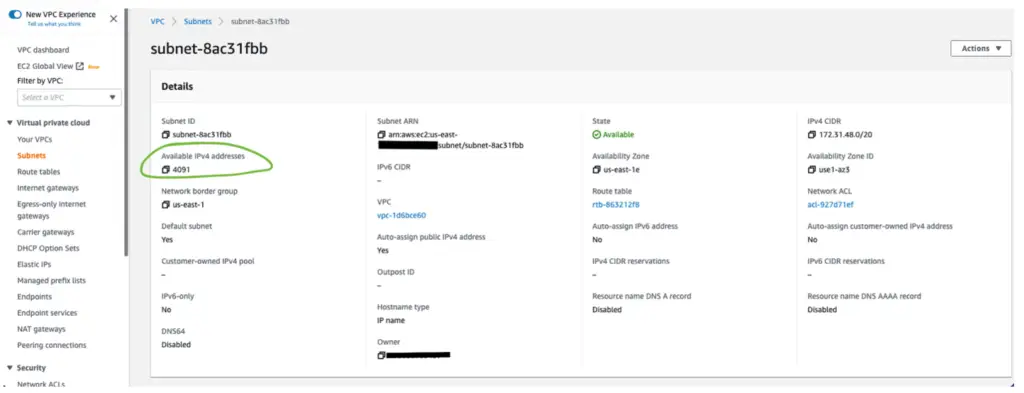
For security purposes, AWS Glue resources are typically deployed within the same subnet with secure access to both the source and target data store established. It’s important to verify that there are enough IP addresses available for the service to use for the EC2 instances creating the Spark environments. You can view the number of available IP addresses from the VPC console as depicted in green in the image below. If there are only a few IPs available and there are several jobs running at the same time, the jobs will have to wait for the resources to become available.
2) IAM Role
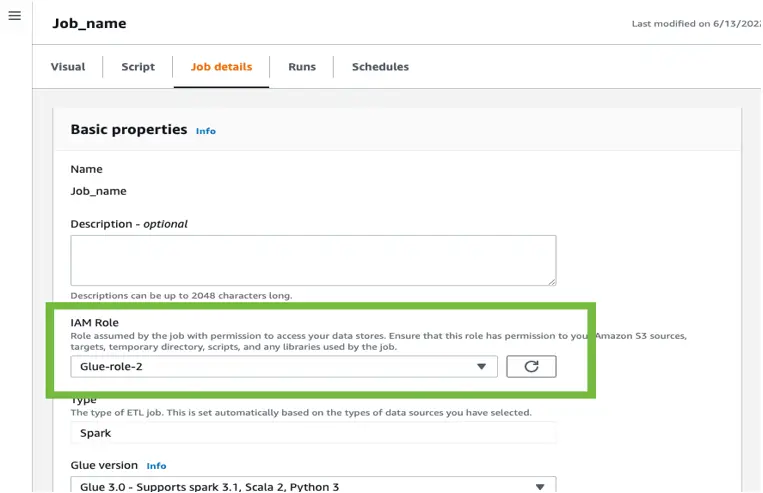
Each job requires an IAM role assigned to grant the job permission to call other services on your behalf. In the AWS Glue Studio console, under “Job Details” you can find the IAM role associated with the job.
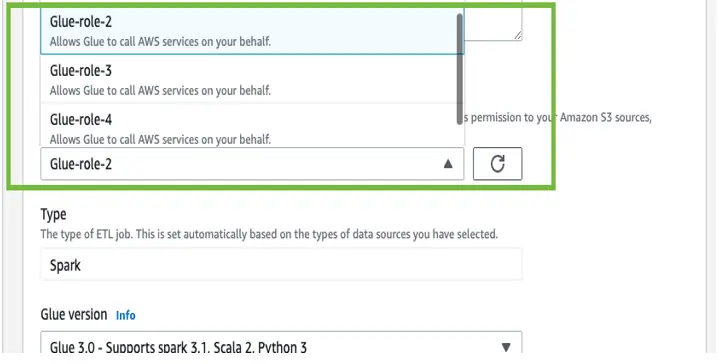
To avoid a bottleneck stemming from the resources the AWS Glue jobs are using, create additional IAM roles with the same permissions, and select a different IAM role for the jobs that run at the same time.
3) Worker Type
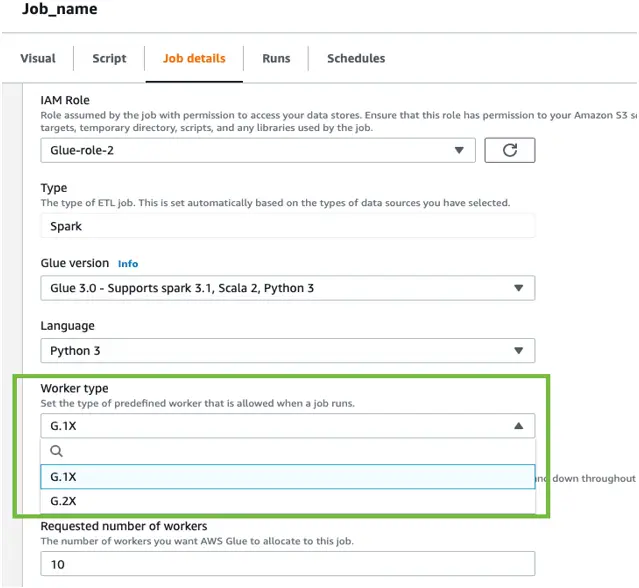
When configuring an AWS Glue job using “Glue version” 2 or later, you can select one of two worker types- G.1X or G.2X. With G.1X, each worker maps to 1 DPU and it provides 1 executor per worker. G.2X maps to 2 DPU and provides one executor per worker. Selecting a different worker type forces the job to create a new Spark environment instead of waiting for an already existing environment to become available. You can change the worker type from the same “Job details” tab.
4) Security Groups
Selecting a different combination of IAM roles and worker types for the jobs running simultaneously should have removed the threat of a bottleneck caused by AWS Glue resource availability. If you’d like to take it one step further, creating multiple security groups with the same permission sets to attach to the connections allows for another combination of factors that determine which cluster of resources AWS Glue jobs will be using.
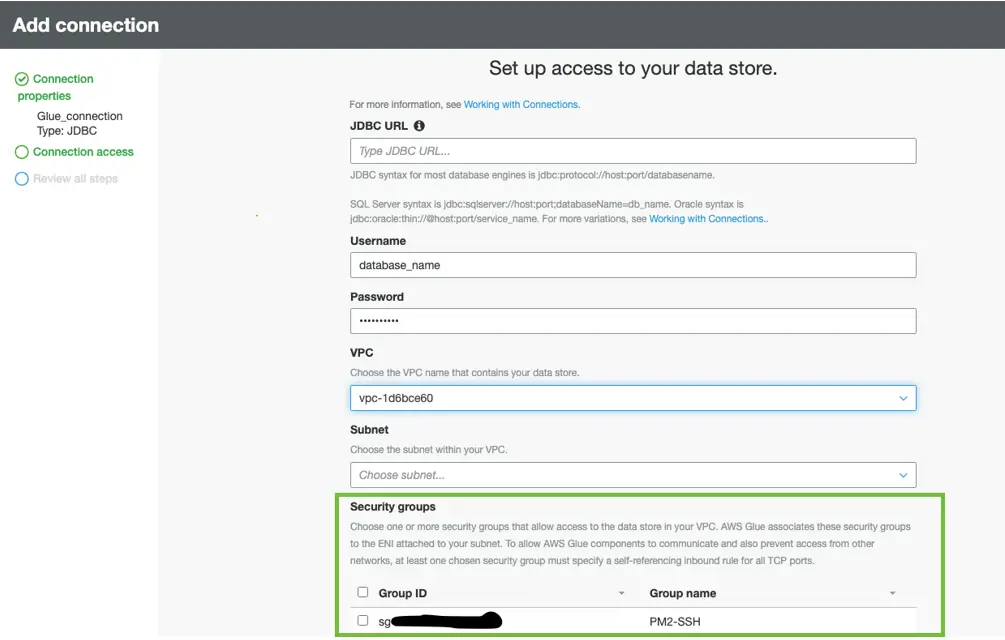
Once all security groups are created with the same permissions, multiple connections to the data source and target can be configured to differentiate between each connection tied to a different set of security groups.
When all the changes have been implemented, the risk of having AWS Glue jobs waiting on unavailable resources to create Spark environments is minimal.
One other issue our team encountered was the common “out of memory” error thrown by Spark. Depending on the volume of returned data, the Spark executors may run out of memory when attempting to load all data into memory prior to transforming the data. Aside from allocating additional DPUs to the job, we discovered a few other options that can be configured to leverage AWS Glue’s parallel reading capabilities and speed up the job.
If your source data is a JDBC data store, you can enable parallel reads, allowing AWS Glue to run parallel SQL queries against local partitions of the data. This link can help you determine whether to use a hash field, hash expression, or hash partition. Creating partitions on the read node allows AWS Glue to read the data in parallel instead of loading all the data into memory potentially running out of memory or slowing down the executors due to uneven distribution of data. In our case, using hash partitions for several jobs has lowered the job runtime from 40+ minutes to ~11 per job run. The image below includes an example of the PySpark script for the job pertaining to the read node.

Alternatively, if your script is sending the query directly to the server and storing the results in Spark Dataframe, the partition can be added in the following way. An upper and lower bound must be established as well as the number of partitions. If the target database is Redshift, it’s highly recommended that the number of partitions is a multiple of the number of slices in your cluster.

When Redshift is the target database, AWS Glue creates files in JSON format in the specified temporary directory in S3. AWS Glue typically writes the temporary data to a total of 20 files. A copy command is then issued to Redshift to load the data. The COPY command leverages Redshift’s massively parallel processing (MPP) architecture to read and load data in parallel. Redshift excels at reading small files from S3 in columnar structure and loading the data.
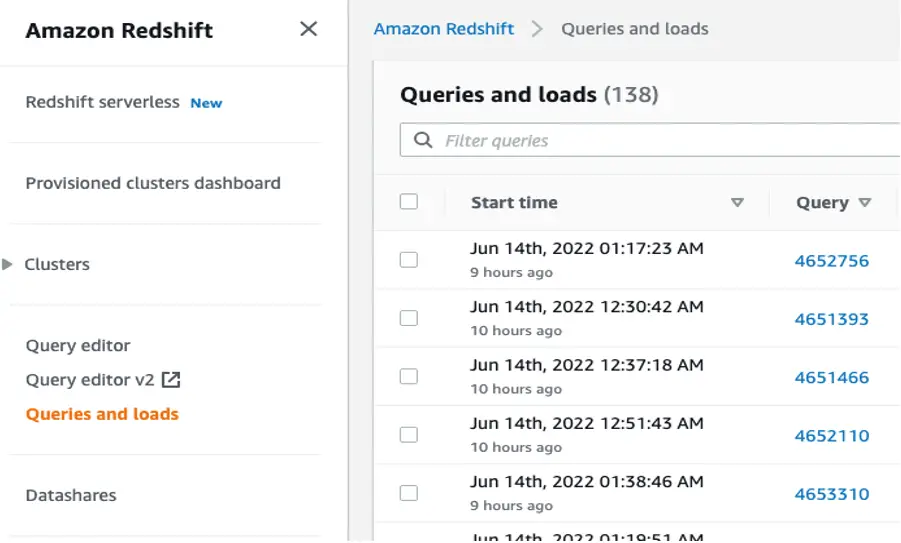
However, if a COPY command is issued to copy all data from a single file that is larger than 2 MB, it may slow down Redshift. To fully take advantage of Redshift’s MPP, it’s important to leverage Spark’s repartition to create multiple smaller files for Redshift to ingest in a matter of seconds instead of a single large file that may take Redshift an hour or longer. One simple way to tell whether Redshift would benefit from additional partitions is to watch the data load in real-time using the “Queries and loads” tab on the Redshift console. If it is stalling and the CPU is spiking above 75, it’s likely that the files loaded are too large for Redshift to process quickly.
The simple solution to avoid this bottleneck is to repartition the data into more files that are smaller in size. Alternatively, if you’re looking to reduce the number of output files produced by AWS Glue, the same solution can apply. In the job script, prior to converting the data frame results to Dynamic Frame, you can repartition into a desired number of files. In the example provided, it partitions the data into 8 files. It’s recommended that the number of partitions are a multiple of the number of slices your AWS Redshift cluster consists of, usually 4 for RA3 nodes.

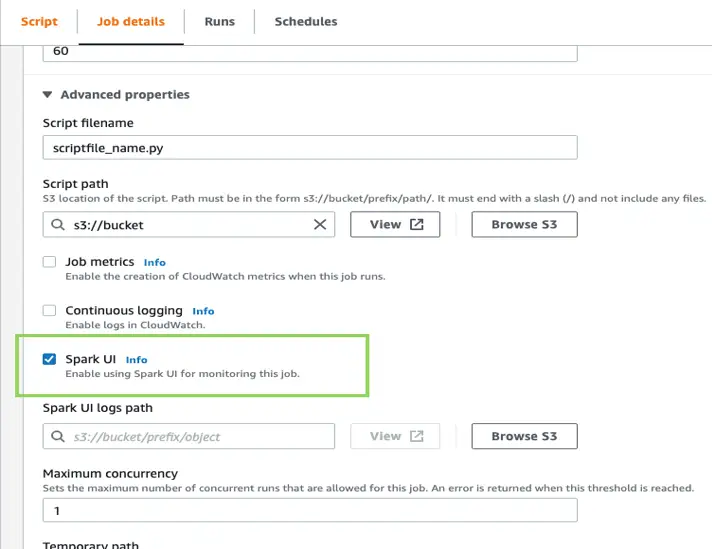
If you still have Spark jobs that are stalling after having followed all the steps above, it’s recommended that you enable the Spark UI under the “Job Details” tab to get a closer look at each step of the Spark job. Details for enabling the Spark UI and monitoring can be found here.
Conclusion
Following the best practices mentioned above can greatly reduce job runtime as well as significantly reduce the potential of AWS Glue and Redshift bottlenecks. Properly configuring AWS Glue jobs can avoid issues down the line and lower job run time in addition to reducing the cost. If your jobs are still running slowly or encountering issues, rest assured, there are more measures that can be taken to improve performance and speed up the jobs although they require a closer look.
Next Steps
If you’re interested in receiving some guidance or additional help with AWS Glue or Redshift, send a message our way! We hope you found this article informative. Be sure to subscribe to our newsletter for PMsquare original articles, updates, and insights delivered directly to your inbox.



