

Share




Chris Chen, January 10, 2021
Get the Best Solution for
Your Business Today!
Let’s say that you and your team have created an enterprise data warehouse for your company. You’ve analyzed the data sources, designed the warehouse, written the ETL, created the processing jobs, and loaded all the data into your warehouse.
Everything is great. Business analysts are happy, operations is happy, management is happy. Everyone loves the data warehouse. Kudos! Smiles in the hallway! An article in the company newsletter! Bonuses for you and the team!
And then the data warehouse becomes a victim of its own success.
Can we have some more? More data, more data sources, more queries, more reports, more dashboards, more-more-more. But with the same hardware, same staff, same budget, same service-level agreements.
Pop quiz, hotshot — what do you do?
Table of Contents
The Cloud?
Yes, the cloud.
You’ve heard the advantages. No servers to buy and maintain, built-in disaster recovery, better data security (no offense), easier mobile device access, etc.
But most importantly, the cloud can give you what you need most: speed and scalability. You need faster servers, more servers. You need them now, yesterday if possible. You’ll likely need more later, too.
What you need is to move your data warehouse to the cloud.
Wait, where are you going? Really, it’s not that bad.
That’s Not What I’ve Heard
Well, let me lay out what it involves. Won’t take long, I promise. I’ll use Amazon’s AWS cloud. You know, just as an example.
Here’s a diagram of AWS Redshift in the cloud:

A Redshift data warehouse is a cluster of nodes that host databases. Each cluster node is the equivalent of a server, and you can resize nodes to fit your needs. For heavier times you can add more nodes, or size up the existing nodes. You can drop down to smaller and/or fewer nodes for the slower periods.
Each Redshift cluster has a leader node that handles communications with external networks. The leader node looks at the requests that come in, figures out how where to get the data, then passes the request to the corresponding compute nodes. The compute nodes pull out the right data, then send it back to the leader node. The leader node assembles everything, then sends it back to the requester.
That Sounds Like A Database
It does, doesn’t it? Where you connect to your database server, the query parser breaks down your query, pulls out the right data, and sends it back.
But in Redshift, the query runs on multiple nodes simultaneously. All the nodes are on a separate network so nothing bothers them. The leader node compiles the code for each request before sending it to compute nodes, so it runs faster. Each compute node can have multiple slices; thus, each compute node can handle more than one request at a time.
Your regular database will cache query results in case a requestor asks for the same data more than once, and Redshift will do that. But Redshift also caches the compiled request code the leader node previously compiled – if you send the same query with just different parameters, the leader node will pass along the cached compiled code to all compute nodes!
Very Nice, But…
There’s more!
Redshift stores the data in columnar form, so queries run even faster. Instead of searching through rows looking for values from multiple columns, Redshift searches each looks through columns for values, then follows grabs the associated rows. Even better, since each column has the same kind of data, those columns can be compressed to load faster and use less disk space.
Instead of searching tables like this:
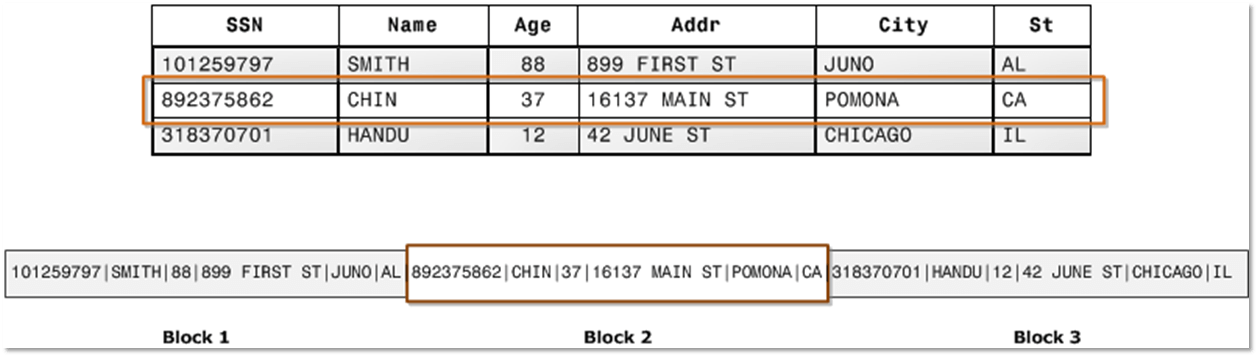
Redshift searches tables like this:

Interesting, Could You…
And you can configure queues and dedicate them to different types of queries! If you have long running queries that aren’t time critical, you can set up a queue and point the queries to that queue. That will keep any smaller, fast-running queries — probably for your report and/or dashboard systems – from waiting around!
You could create another queue for your ETL processes so they are also not blocked by other queries!
Fast. Efficient. Scalable.
…
I got carried away, didn’t I?
Well… Yes.
I’m sorry, I get excited about great tools.
Onward!
How Would I Put My Data Into AWS Redshift?
AWS has a tool for that, called AWS Glue. You can point Glue to your own database and it will extract the data, or you could upload extracts into AWS’ cloud storage, AWS S3. You can write Python scripts to have Glue perform any transformations you need. Glue will extract the data, run the transforms, and save your data to S3, then tell Redshift to import the data from S3. Redshift will handle the columnar storage and data compression during that import.
If you need to insert just a little bit of data, you can connect to Redshift over an ODBC or JDBC connection and issue SQL commands. Redshift presents as a PostgreSQL server, and you can write your own SQL functions, stored procedures, and even materialized views.
Voila – data warehouse!
What About Reading Data From AWS Redshift?
Easy peasy! Since Redshift acts like a PostgreSQL server, you can point your SQL query tools, reporting or dashboarding software, even Microsoft Excel, to Redshift and it will handle your SQL queries.
Redshift can also do large extracts of data to AWS S3 without affecting Redshift’s responsiveness!
Okay…What’s The Catch?
No catch, really! Keep in mind – you can use as much or as little of AWS as you like.
If you don’t have time or resources to change your ETL processes, you can use what you have then bulk upload the results to Redshift. You might have a certain part of your data warehouse that’s frequently used or takes a long time to build, you could put that in Redshift. You could bulk upload new data to Redshift, transform it into your warehouse format, then download it to your local warehouse.
The hardest part of the cloud is switching your thought processes from “buying” to “renting”. In the traditional model, servers are bought upfront and ongoing processing has much smaller costs. Running multiple queries against your database servers costs virtually nothing; you’ve essentially prepaid for – bought – them.
In the cloud, the initial costs are small but you’re paying for ongoing usage. You haven’t purchased anything physical so there are no capital costs, but each month you’ll get a bill for the resources you’ve used – your rent. My colleague Chris Chapman wrote an article that explains this concept in depth.
The crucial advantage of the cloud is the time and money you don’t need to spend building and maintaining servers. No more purchase orders, no more server or database patches to apply at midnight Sunday, no more emergency replacement hard drives or memory. AWS takes care of that for you.
Now you can handle all that other work you need to do.
Next Steps
I hope you find this article helpful, fun, and generates some useful ideas. Be sure to subscribe to our newsletter for data and analytics news, updates, and insights delivered directly to your inbox.
If you have any questions or would like PMsquare to provide guidance and support for your analytics solution, contact us today.


