
Share




Christopher Penn, September 30, 2019
Get the Best Solution for
Your Business Today!
Introduction
The recurring perception that artificial intelligence, AI, is somehow magical and can create something from nothing leads many projects astray. That’s part of the reason that the 2019 Price Waterhouse CEO Survey shows fewer than half of US companies are embarking on strategic AI initiatives – the risk of failure is substantial. In this series, we’re examining the most common ways AI projects will fail for companies in the beginning of your AI journey. Be on the lookout for these failures – and ways to remediate or prevent them – in your own AI initiatives.
Table of Contents
The AI/Machine Learning Project Lifecycle
Before we can discuss failures, we need to walk through the AI project lifecycle to understand what should be happening. Grab the full-page PDF of the lifecycle from our Instant Insight on the topic and follow along.
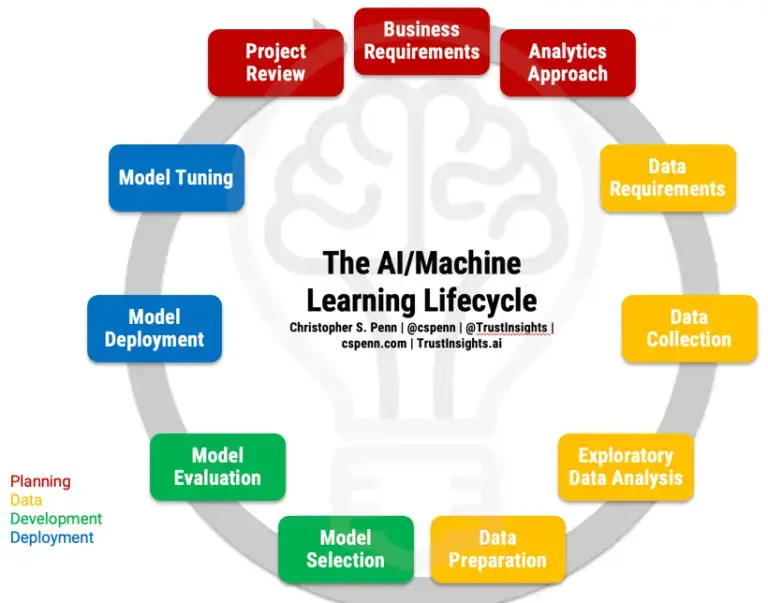
First Stage: Planning
No project succeeds intentionally without solid planning, and AI is no exception. Before anything else, determine what are the business requirements of the project. The goal of any AI project is to do one of two things:
- Recognize and analyze things that humans could do, but don’t scale very well doing (think millions of images to analyze)
- Predict and forecast things that humans can’t do very well or at all (think massive predictive and driver analytics)
However, above these two broad use cases, businesses care about three things:
- Increase operational speed
- Increase quality of results and outcomes
- Reduce costs
When setting out business requirements for AI, we need to establish which of these business outcomes our project will serve (why), along with who is responsible, what we’ll be doing, when, and how.
Following our business requirements, we must next tackle our analytics approach. How will be achieve those business results? What methodology, what strategy will we use? Are we tackling a problem where we know what outcome we’re trying to solve for, and we have massive amounts of data? That’s supervised machine learning.
Are we tackling a problem where we have massive amounts of data and we don’t know what we’re looking for? We want machine help to make sense of our data, to create order from chaos – that’s unsupervised learning.
Think of planning and analytics approach as the design of the restaurant and the menu in cooking. Before you could do anything else, you’d want to know what the menu would be.
Based on our chosen analytics approach, we move onto data.
Second Stage: Data
The lifeblood of machine learning is data. Without data, we have nothing to train our machines with. The data stage is broken into four parts.
First, we need to specify data requirements. These are the requirements of our data – and this list varies with every project. Use this as a starting point for determining your own list of data needs.
- What data will we need?
- What format will that data be in?
- Where will the data come from?
- What are the compliance requirements of the data source?
- How often will we need the data?
- Who is responsible for maintaining the data?
- What security measures will we need?
- How will the data be used?
- What, if any, will be published or made available?
This list is by no means comprehensive, but it’s a good starting point for your own data requirements. Once we’ve specified our data requirements, we need to set up data collection. This stage typically requires the help of people like developers, data architects, database administrators, and other data engineering professionals to extract data from where it lives in our organization or from trusted third-party repositories.
After data collection, we begin the formal process of exploratory data analysis. This stage essentially validates our data requirements:
- Did we get the correct data according to our specifications?
- Is the data in good condition – statistically valid, free of errors and omissions?
- Does the data fit our needs?
- What, broadly, do we see in the data that confirms or negates our overall analytics approach?
- What are the main characteristics and attributes of our data?
- What else came along with the data that could expand our approach?
Finally, the last step in the data stage is data preparation. This is the art and science of preparing our data for use by machine learning algorithms. Data preparation often involves tasks such as:
- Feature engineering, to add, subtract, or change our database
- Anomaly detection/correction
- Error correction
- Encoding to formats that machines can understand (especially deep learning, which requires converting most data to numbers)
Think of the data stage as the preparation of ingredients in the restaurant analogy.
With our prepared data in hand, we’re ready to move onto the next stage, modeling.
Third Stage: Modeling
Modeling in machine learning is the process, either manually or in an automated fashion, of selecting which specific machine learning algorithms we’ll use and building a model – essentially software – to work with our data.
Modeling begins with model selection. Based on the type of analytics approach we selected in the first stage, most data scientists should know what measure of correctness, accuracy, or error a model should adhere to. For example, regression-type models (supervised learning) often use measures such as root mean squared error (RMSE) or r^2 to indicate the level of error in a model, and our goal is to find models with the lowest error rate. Other problems, like categorization and classification models, will use measures such as area under curve (AUC) Receiver Operating Characteristics (ROC) to help us understand how well the model distinguishes between its categorizations.
With tools like AutoML and IBM AutoAI, model selection can be accelerated by having machines programmatically test common models and deliver analysis of which models perform best, speeding up the process dramatically. Once selected, we train the model on a subset of our data called the training data, usually 60-80% of our available data.
Based on our selection, we’ll then test the model using another percentage of our data (holdout and validation data, typically 20-40%) to see how well it performs with additional data, evaluating the error rate on a subset of our data that we didn’t use for the training. This stage, model evaluation, helps prevent a problem called overfitting, when a model works perfectly with past data, but then performs very poorly with future data it didn’t anticipate.
Think of model selection and model evaluation as the creation and test kitchen in the restaurant analogy, before a recipe goes to the main restaurant.
Once a model has passed evaluation, we move on to deployment.
Fourth Stage: Deployment
Once our model is completed and evaluated for accuracy, we move onto model deployment. Machine learning models are very much pieces of software; once you build an app, you have to release it for your end customers to use, or all that effort was for nothing. This is the distinguishing difference between data science and machine learning; while they share many common practices and techniques, in data science the exploration and analysis is typically the final product, while the production model (software) is the final product in machine learning.
We deploy our model in some kind of server environment where new data can flow into it and the model makes an analysis and then sends its analysis onto another system; for example, a model that’s analyzing sentiment from tweets would take in new tweets, score them, and then send those scores to a social media management app or a customer service app for us to do something with them.
However, deploying the model itself isn’t enough; we also need to make sure the model is continuing to perform well. This is model tuning, when we retrain our model based on new production data that has come in, to ensure the model remains fast and accurate. Extending our customer service example, we’d quality check our tweets to ensure the model continues to accurately score which tweets are positive and which tweets are negative. Tuning also involves verifying the model isn’t drifting or becoming biased in an unacceptable fashion.
Think of deployment and tuning as the actual serving of our meals in the restaurant and getting feedback from customers about what they did and didn’t like about the food.
After Action
No project is complete without a review of its successes and failures; machine learning is no different. Every project should have an after-action review to sum up lessons learned, to organize useful code and data for future projects, and to ensure we address any training and professional development gaps in our team.
Conclusion
Part I: What Could Go Wrong?
Now that we have an understanding of the basic AI/machine learning lifecycle, we’ll next dig into each of these stages to highlight what’s likely to go wrong, what’s gone wrong in our past experiences that we can learn from. Stay tuned! If this topic has grabbed your attention then make sure you check out our webinar:
Webinar Information
Advancing from Cognos Analytics to AI
Wednesday, November 13, 2019
1:00 PM – 2:00 PM
Next Steps
We hope you found this article informative. Be sure to subscribe to our newsletter for data and analytics news, updates, and insights delivered directly to your inbox.
If you have any questions or would like PMsquare to provide guidance and support for your analytics solution, contact us today.



