

Share




Aastha Poudel, August 12, 2024
Get the Best Solution for
Your Business Today!
Introduction
Have you wondered how to make AI models tailored to your business’s specific information? At PMsquare, we regularly see our customers needing to enhance their AI applications with up-to-date and more personalized data. Use cases for this will vary, but the core reason is simple – large language models (LLM) are powerful, but if they don’t know details about a specific topic or business then their uses will be limited. One way to teach a LLM about a specific topic is to go through a fine-tuning process which will further train a pertained model on additional data.
However, fine-tuning a model can be time consuming and costly. This has led to the rising popularity of retrieval augmented generation, or RAG. RAG is a technique that combines an external knowledge base, or collection of documents, that is queried when a prompt is sent to a model. The model will then use the information from the knowledge base when generating its response. This enables the model to produce fine-tuned like responses without spending the time and money to fine-tune the model. There are two core components in a RAG technique – retriever and generator. The retriever gathers external sources that are relevant pieces of information related to the query. This retrieved information is used by generator to construct contextually correct responses.
Amazon Bedrock is a fully managed service from AWS designed to quickly build and scale GenAI applications and workloads. With Knowledge Bases for Bedrock, a fully managed end-to-end RAG workflow can be created and deployed. This can then be integrated with existing applications to provide real-time retrieval of relevant information, enhancing the accuracy and reliability of the generated responses. Below is a basic architecture of how this type of a deployment can work within Bedrock.
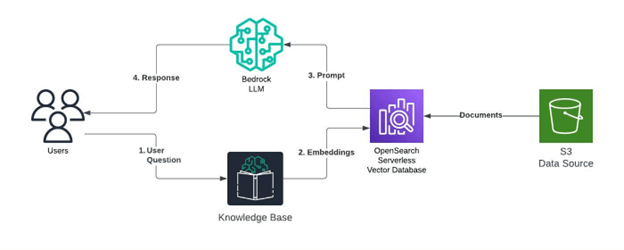
Next, let’s explore how to create a knowledge base, or vector database, for a RAG implementation using Bedrock.
Table of Contents
Creating a RAG Knowledge Base with Bedrock
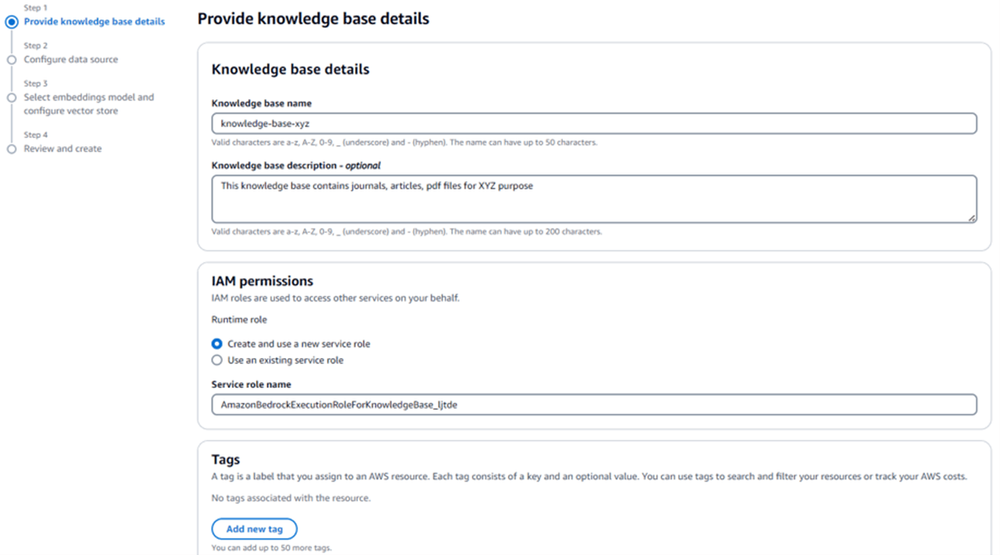
A knowledge base can be created using either the console or an API call. For this example we will use the console. First, provide the required details such as name, necessary IAM roles, and tags. If using an existing service role, make sure it has permissions attached following the principle of least privilege.
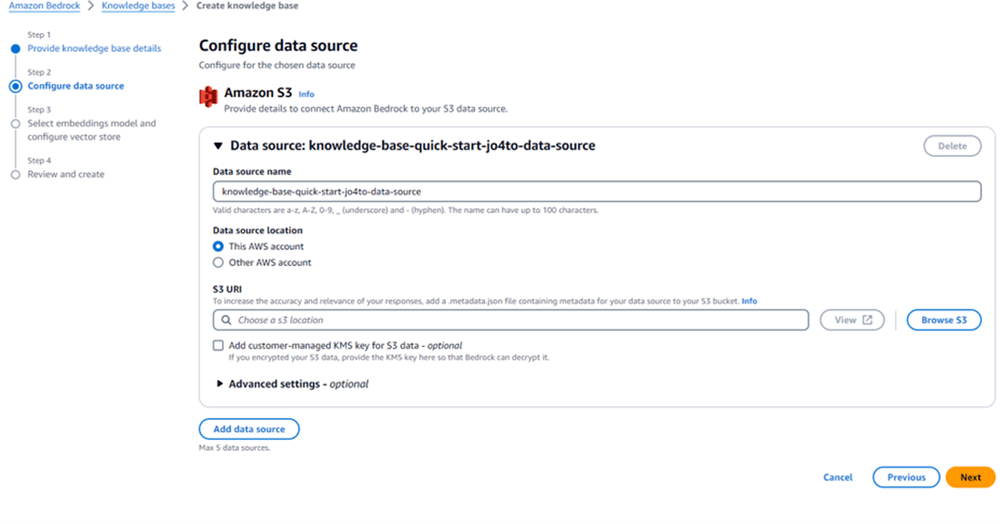
Next, the data source needs to be configured for the knowledge base. Use the S3 URI that contains the data and documents relevant to thisworkload. If the S3 data is encrypted using a KMS key, make sure to enable the option to add it.
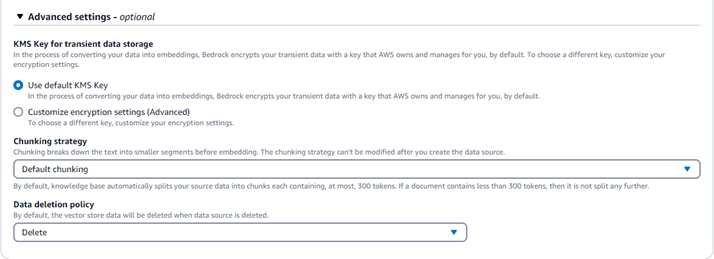
In the additional settings, the chunking strategy can be defined by selecting one of the following options:
- Default Chunking: Automatically chunks data such that each chunk has at most 300 tokens.
- Fixed Size Chunking: We can define the max tokens and overlapping percentage of the chunks.
- No Chunking: Leaves the data unchunked, storing it as a whole.
Data retention policies can be configured as well. This should be used carefully. If the source data is removed it’s unlikely the knowledge base will be needed. So just be aware of the implications of enabling this behavior.
The next step is to choose the embedding model. Select the model that best aligns with the use case requirements to ensure optimal performance and relevance to the data. There are two options that can be selected in the vector database section:
- AWS-Managed Vector Store: Let AWS create a vector store for us in Amazon OpenSearch Serverless. This option simplifies the setup process, as AWS handles the creation and management of the vector store, ensuring scalability and integration with other AWS services.
- Existing Vector Store: Choose from an existing vector store if one is already set up. This option allows us to leverage our current infrastructure and configurations, providing flexibility and potentially reducing setup time.
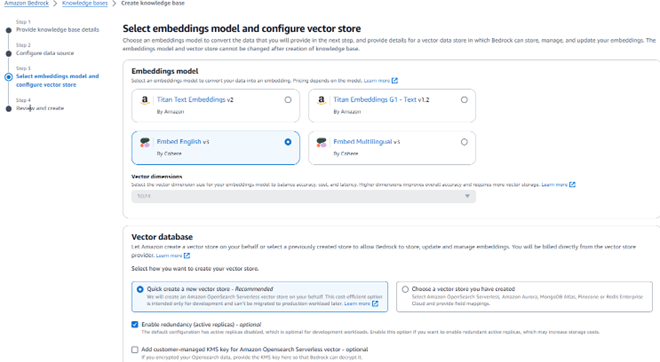
The final step is to review the configuration and create the knowledge base. Make sure to thoroughly review the configuration as some features cannot be updated once it is created.
Now that the vector database has been created there are two ways they can be leveraged in Bedrock.
Leveraging Your Vector Database in Bedrock
The first is with an Amazon Bedrock Agent. An agent is a feature within Bedrock that facilitates user-based conversations by orchestrating between the foundational model, data sources, and defined actions. When creating an agent, we provide instructions, define action groups for specific tasks, and add a knowledge base. The agent then manages API calls and coordinates these components to perform the desired tasks.
Here, we will add the knowledge base that we previously created and provide a description about it that will be integrated as instruction in the bedrock agent.
The second option is through an API call. The RetrieveandGenerate API call will directly query the knowledge base. If the requirements to only generate a response using information from the knowledge base, and no other actions are needed from the application then the application can directly query it at runtime using the API. Additionally, there is an option to choose a Foundational model that will augment the result retrieved from the knowledge base query and generate a response that fulfills the context and purpose of our query.
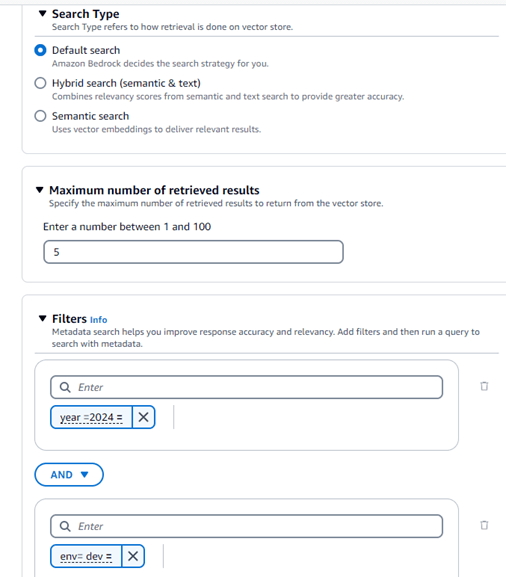
For more advanced implementations the search type can be defined to customize how information will be retrieved. The different retrieval options are below:
- Default search: This will let Amazon Bedrock decide the best search strategy for our knowledgebase query.
- Hybrid search (semantic & text): This will combine semantic and text search score and enhance the accuracy of our retrieval
- Semantic search: This will use the vector embedding with semantic approach to query our knowledge base.
Additional inference parameters can be configured as well, such as setting the maximum retrieved result count. The metadata file in the S3 bucket can filter queries based on attributes within these files. This can be done using various operators like equals, notEquals, startsWith, and logical operators such as AND & OR. These filters ensure that responses meet specific requirements categorized by the metadata attributes. These features can also be tested directly from the Bedrock console.
Conclusion
With Amazon Bedrock, implementing a fully managed RAG workflow is greatly simplified. Bedrock handles the management and configuration of the knowledge base infrastructure. This allows developers to concentrate on optimizing the retrieval and generation processes to ensure the most accurate and relevant responses, improving the overall effectiveness of the system.
Published Date:



