

Share




Dan Swan, June 9, 2022
Get the Best Solution for
Your Business Today!
Incorta is a direct data platform that delivers an end-to-end self-service data experience. Incorta consolidates data management and analytics into a single integrated platform for data acquisition, storage, analysis, visualization, and reporting without the cost and complexity of traditional solutions. Incorta combines an open data lake with in-memory analytics for both durable storage and responsive queries. Multiple workloads can be served with the built-in Spark engine, including big data processing, data enrichment, and machine learning.
Table of Contents
Incorta’s philosophy incorporates four core tenets of a modern analytics platform:
- No data left behind
- Speed and simplicity
- Secure, governed self-service
- Focus on the user
An Incorta installation should;
- Eliminate the need for a data warehouse and its associated star-schema iterations and relational-based queries
- Allow IT to easily aggregate and secure complex data
- Enable all users to view joined data in real-time
- Empower non-technical business users to access a centralized data repository to analyze the data any way they want, on their own, without delay
How does Incorta achieve these goals? We will first look at how data flows within Incorta, then review its major components.
Incorta ingests data from a source using the table structure and joins of the source data, which means your source data does not need to be modeled as intensively as you would in a data warehouse. You have the option to allow Incorta to create joins automatically, based on the existing foreign key relationships between your source tables. Using the Table Editor or Join Editor, you can edit or remove joins as well as create new joins. You can limit the columns you extract from a particular table to control exactly what and how your source data is loaded. Every company has more than one source of data and Incorta is built to integrate multiple sources.
Data can be loaded as frequently as necessary, scheduled or manual, guaranteeing up-to-date data. Also, you have the choice of performing full or incremental data loads.
From data acquisition, you can configure a schema to optimize your data based on your analysis and reporting requirements. An Incorta Schema will contain the tables and joins established during the load process. Incorta also provides the capability of building business schemas that provide users with a business-friendly view of the data, making it easier for novice or seasoned users to create their own reports. Business schemas provide a semantic layer of standardized business terminology for the organization and pre-defined formulas and calculations.
Reports and insights can be created within Incorta, or a user can consume Incorta data using their favorite interface, such as Excel, Tableau, Power BI, etc. With Incorta your users are not locked into a single reporting or analysis application – there are many options.
Incorta can run on commodity hardware – no special appliances are required as with some data warehouses.
Data Flow within Incorta
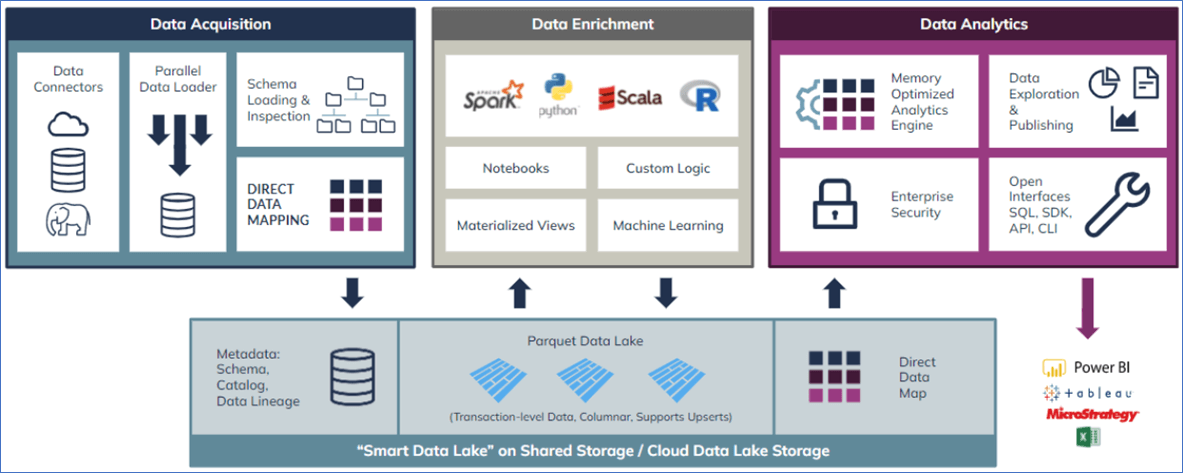
Data Acquisition
Data Acquisition encompasses the processes and tools that Incorta uses to acquire and load data. Data Connectors (which are included in an Incorta installation) provide the means to connect to an external data source. Parallel processing means multiple tables can be loaded at once and Direct Data Mapping ensures the source structure is loaded and maintained along with the data.
Connectors
A Connector is a protocol, service, or Application Programming Interface (API), which specifies how Incorta can connect to an external system or application and ingest data. Incorta includes many out-of-the-box connectors for data acquisition. There are connectors for applications such as NetSuite and Oracle and there are connectors for databases such as IBM DB2, MySQL, and Oracle. There are also connectors for data lakes, query services, file systems, and streaming data. Currently there are over fifty connectors available within Incorta. Connectors enable Incorta to ingest data as it is structured in the source systems.
Below, is an edited view of some of the available connectors. When creating a new data source, you will be prompted to choose an appropriate connector for your data.

The Loader Service
In Incorta, a service is a Tomcat instance running with a specific configuration provided by the user. All services on the same node share the same Tomcat binaries and same incorta.war file. Logs are different from one service to another of course.
In a multi-threaded fashion, the Loader Service reaches out to the source system and replicates the data in a three-phase process;
Extraction
- The Loader Service extracts records from data sources and writes them into parquet files.
- The Loader Service can extract multiple tables in parallel, depending on object dependencies and the availability of threads in the table thread pool. If a physical schema table contains multiple data sets, the Loader Service can also extract these data sets in parallel. Furthermore, if you configure a data set to use chunking (parallel extraction), the Loader Service also extracts this data set in multiple threads.
- At the end of the extraction phase, if compaction is enabled, a compaction job starts to create a compacted version of the extracted parquet files with no duplicate records.
Transformation
- This is the first actual phase in a full or incremental load for a materialized view or SQLi table. The Loader Service submits queries to Spark to process these queries and waits for them to finish. Spark then creates new parquet files in shared storage for these objects. At the end of the transformation phase, if compaction is enabled, a compaction job starts to create a compacted
Load and Post Load
- For physical schema tables and materialized views that have performance optimization enabled, the engine loads data from the source parquet files into its memory.
- After loading (post-load process) and in the case that a loaded object has one or more key columns, formula columns, load filters, or joins (as a child table), the engine calculates them and writes snapshot Direct Data Mapping files.
- During the post-load process, the engine also calculates Incorta Analyzer tables and Incorta SQL tables, and then the Loader Service writes full parquet files for these tables.

The load process can execute a full load quickly. In the example below, the load for the online store took 2 minutes, 38 seconds to load 31 tables, 3 of which have millions of rows.

Data Enrichment
Data Enrichment broadly means the application of human intelligence on the data, metadata and the relationships between the tables. It also means the application of machine learning and data science. The tools in the enrichment phase include Notebooks, which are an Incorta tool for building materialized views and applying machine learning. The Notebook Editor is an interactive Apache Zeppelin notebook environment that allows you to explore, manipulate, and transform data for a materialized view in a physical schema. The Notebook Editor supports several languages including PySpark, R, Scala, Spark SQL, and PostgreSQL. You can use the Notebook Editor to iteratively code and explore your data before saving code for the materialized view.
Direct Data Mapping
Direct Data Mapping is an in-memory process within the Loader Service that detects, then establishes the joins between tables based on the existing joins in the data source. The data is then compressed and stored in Parquet files. The resulting Direct Data Mapping files support the query engine within the Analyzer Service. Direct Data Mapping enables real-time analytics on top of original, transactional data commonly found in ERP systems, so you no longer have to know ahead of time how to design the data tables or pre-define the questions you want to ask of the data. You will not need to transform data prior to analysis or involve IT to build everything for users.
Direct Data Mapping Approach
- Connects out-of-the-box to: Big data (Hadoop, Hive, Kafka, NoSQL), Cloud applications (Salesforce, ServiceNow, NetSuite, etc.), Databases (Oracle, MySQL, SQL Server, DB2, Teradata, etc.)
- Relates tables based on their existing relationships within the source system
- Leverages 1:1 data mapping to preserve the data’s original shape and security parameters, eliminating the need for ETL
- Persists data as parquet files in HDFS, allowing it to be leveraged by other Big Data tools
- Serves data to any SQL-compliant front-end or provides access to data through Incorta’s own visualization tier
- Maintains security centrally in the Incorta platform, rather than in each tool
- Eliminates need to pre-aggregate and pre-calculate data—no data transformation or data warehouse required
Direct Data Mapping accelerates the load process and supports the Incorta query engine by pre-processing incoming data to discover all potential query paths.

Data Analytics
Within the Analytics Service are the key pieces that support data analysis within Incorta and support access to data via third-party analysis tools. The Analytics Service utilizes the Direct Data Mapping files to reduce data retrieval times and Runtime Security is used to apply row-level access to the data. The Analytics Service can access physical schemas and Business Schemas, so users are free to explore all data within Incorta depending on their security access.

Data Analytics is the part of Incorta where a user can create Incorta Insights that can encompass list reports, aggregated reports, crosstabs, and various visualizations. The data analytics segment also supports access to Incorta data by other data analytics tools like Power BI, Tableau, and Excel. As mentioned earlier, the Direct Data Mapping files support the Analytics service, enabling the fastest query response.
Below is an Incorta Insight displaying a KPI report on top of two visualizations.

Below an Incorta visualization and an aggregated report on the far right and a crosstab or pivot table on the bottom.

Incorta Components
Incorta can be broken down into a few major components: the Cluster Management Console, Clusters, Incorta Nodes, the Loader Service, and the Analytics Service. Below is an illustration of a single Incorta Cluster.

The Cluster Management Console (CMC) is a web UI application that becomes available after Incorta has been installed.
The CMC is designed to allow administrators to:
- Create and manage a cluster.
- Create and manage Incorta nodes.
- Create, add, start, or stop a loader and analytics service in a cluster.
- Create, import, or export a tenant.
- Filter and view log files for tenants, services, by date, and by service type.
- Set default configuration options for:
- Servers
- All tenants
- Individual tenants ()
A Cluster defines an SQL interface port, connection pool size, proxy read timeout, and other settings. A Cluster can hold everything you need to operate Incorta, from loading to analysis and reporting.
An Incorta Node is a physical container of services running on the same machine. Normally you would install one node per machine. An administrator can configure a number of services to be running on the machine hosting that node. The machine should be configured with adequate size and power to handle the expected workload. Once a node is installed it can be federated under a cluster. After federation, no other cluster can federate it. A user can configure services for a node remotely using the CMC interface. A user has the option to set all parameters of a new service like heap size, HTTP ports (for Analytics only), email configurations, CMC login credentials, Spark integration settings, and others. A service cannot be started until it joins some cluster.

Security within Incorta
The Security Manager allows you to create and manage users and groups to both enable sharing and restrict access. Using built-in Security Roles, you are able to assign access permissions to groups of users. Known as a Role-Based Access Control (RBAC), you can easily enforce access to certain features and functionality within Incorta.
The Security Manager can be accessed from the Security tab in Incorta.
Within the Security tab, an authorized user can add users and groups, and they can assign users to Groups and assign Groups to Roles. Users and Groups can be edited, added or deleted, but the Roles are fixed. The relation between users and groups is many-to-many. A group can have multiple users and a user can be a member of multiple groups. Thus, the same user or group can have multiple records or rows in the assignment table(s).

Security Roles establish permissions* to Incorta functions.

*Permissions apply to Incorta functions assigned to the Roles. Access rights refer to an individual’s access to an object, such as a table, view or a subset thereof. A user can grant access rights to another user to view a dashboard, for example.
Users and Groups can be edited, added, or deleted one by one in the Security Manage. However, a CMC Administrator or Super User can import users in one of two ways;
- Import and synchronize Incorta users and groups with a physical schema in Incorta
- Import and synchronize Incorta users and groups with domain users and groups using LDAP
In both cases, you will have to import a .Properties file that maps the physical schema object columns to Incorta user and group details, or if importing domain users then the .Properties file should map the LDAP attributes to Incorta user and group details. You can either create the .Properties file from scratch or download a template file and update it.
Summary
Incorta’s mission is to help data-driven enterprises be more agile and competitive by resolving complex data analytics challenges. By capturing, storing, and enriching your multiple data sources with minimal processing, you can have unprecedented access to analyze your up-to-date data.
For more details on everything in this article and more, go to https://docs.incorta.com for the latest documentation.
Next Steps
We hope you found this article helpful! If you need help with Incorta or just want to talk shop, reach out to us!
Be sure to subscribe to our newsletter to have PMsquare original articles, updates, and insights delivered directly to your inbox.

